MoE 架构
- MoE 架构的基本思想、计算。
- MoE 在训练、推理与微调中的关注点与策略。
- 实践中的关注点与使用建议。
1. MoE 介绍
1.1 起源
2023 年,随着 Mixtral 8x7B 模型的推出,一种被称为 MoE 的模型架构在开源人工智能社区引发广泛讨论。
MoE (Mixture of Experts 混合专家) 模型的理念起源于 1991 年的论文 Adaptive Mixture of Local Experts。
与 Transformer 相比,它是一种 稀疏 模型架构:模型内部放置多个专家模块,每个 token 只激活其中一部分专家参与计算。
1.2 特点
我们知道,模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
MoE 的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。MoE 可以在扩大模型总参数量的同时控制每个 token 实际参与计算的参数量。这样可以提高模型容量,但单 token 的计算成本不必与总参数量等比例增长。
与 Transformer 这种稠密模型相比,MoE 有下面几个特点:
- 预训练方面:预训练速度更快
- 推理方面:得益于只激活模型中的一部分专家,与具有相同参数数量的模型相比,MoE 具有更快的 推理速度
- 硬件方面:需要 大量显存,因为所有专家系统都需要加载到内存中
- 微调方面:在 微调方面往往面临泛化能力不足和引发过拟合的问题,但在指令微调方面具有很大的潜力。
1.3 基本概念
常见 MoE 模型包括 Mixtral、DeepSeek-V2 / V3、Qwen-MoE、Grok 等。不同模型的实现细节不同,但核心问题基本都围绕几个概念展开:
- Router / Gate Network:路由 / 门控网络,决定每个 token 使用哪些专家。
- Expert / Sparse MoE Layer:专家 / 稀疏 MoE 层,指被路由选择的专家模块,通常是 FFN / MLP。
- Sparse Activation:每个 token 只激活部分专家。
- Load Balance:避免少数专家过载,保证训练和推理稳定。
2. 基本思想: 条件计算
传统 Transformer LLM 通常是 dense 模型。所谓 dense,是指每个 token 都会经过每一层中的主要参数。
简化表示:
Dense Transformer Block
token -> Attention -> FFN -> output
其中,FFN 对所有 token 使用同一组参数,并且 Dense FFN 通常占据 Transformer 参数的大部分。
在 MoE 中,Transformer 模型中的每个前馈网络 (FFN) 层被替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络作为路由和若干数量的专家。
每个 token 通过路由选择少数几个专家参与计算,即 MoE 的目标不是让所有专家同时工作,而是让不同 token 动态选择更合适的专家。
这样儿,MoE 在显著增加模型容量的同时保持 Attention、RoPE、RMSNorm、Residual 等主干结构相对稳定。
MoE Transformer Block
token -> Attention -> Router -> Top-k Experts -> Combine -> output
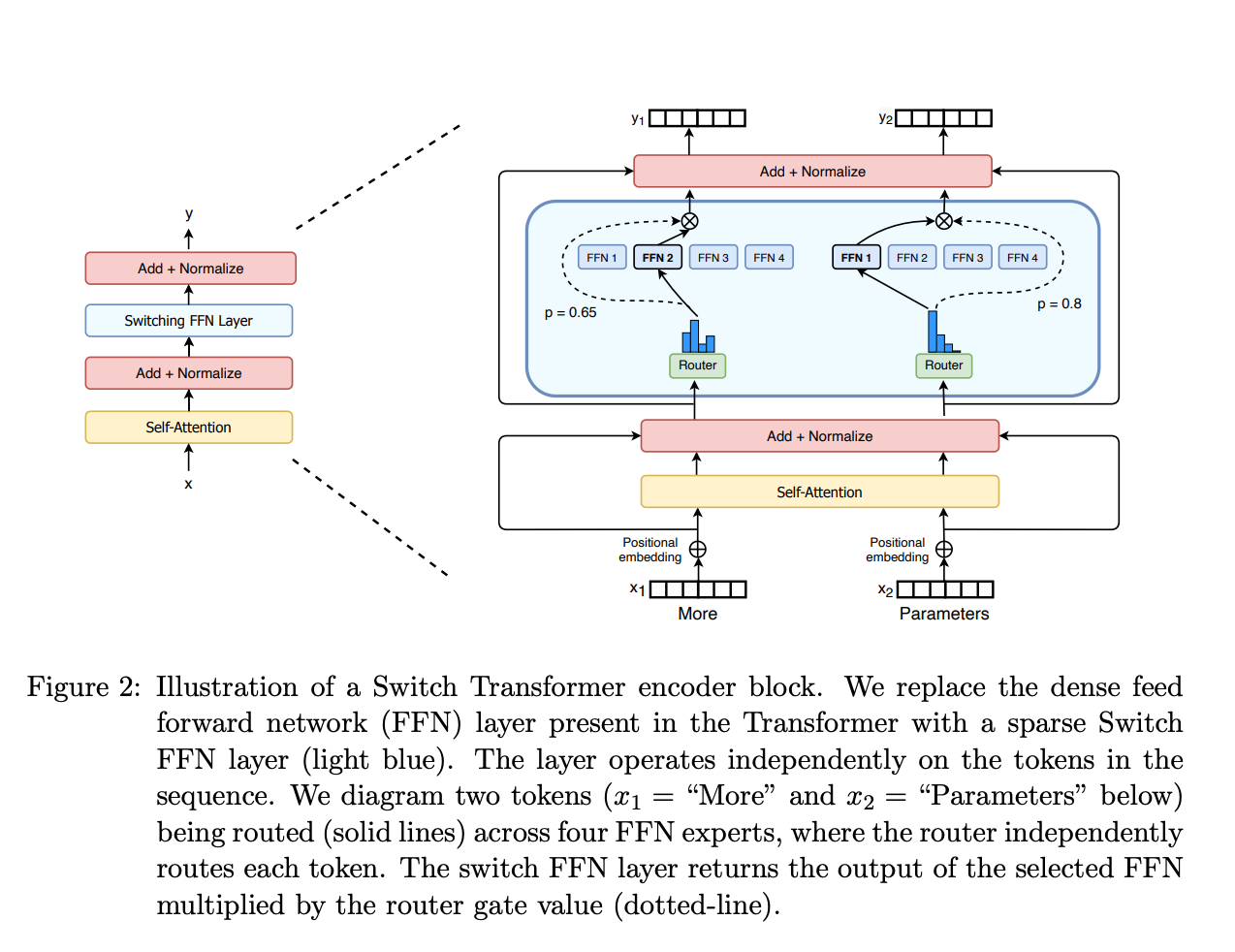
Dense 与 MoE 两者的关键差异如下:
| 维度 | Dense 模型 | MoE 模型 |
|---|---|---|
| 参数使用 | 每个 token 使用同一组层参数 | 每个 token 只使用部分专家参数 |
| 总参数量 | 与每次计算量强相关 | 可以很大,但激活参数较少 |
| 推理计算 | 结构稳定,调度简单 | 需要路由、专家调度和结果合并 |
| 训练难度 | 相对成熟 | 需要处理路由、负载均衡和并行通信 |
| 工程复杂度 | 较低 | 较高 |
2. MoE 层的计算
MoE 层的计算可以粗略概括为:
路由 -> Expert 计算 -> 合并
2.1 总参数量与激活参数量
MoE 模型经常同时标注 总参数量 和 激活参数量。例如:
总参数量: 100B
激活参数量: 20B
这表示模型包含 100B 参数,单个 token 前向计算时只使用其中约 20B 参数。
需要区分几个指标:
| 指标 | 含义 |
|---|---|
| 总参数量 | 模型所有参数,包括所有专家 |
| 激活参数量 | 单个 token 实际参与前向计算的参数 |
| 权重显存 | 加载或分布式存放模型权重所需的显存 / 内存 |
| 计算量 | 单个 token 实际产生的 FLOPs |
MoE 可以降低"每 token 计算量相对于总参数量的比例",但不意味着总显存需求一定很低: 所有专家权重仍然需要被加载,或通过分布式方式存放。
2.2 Expert 专家
Expert 通常是一个独立的 FFN / MLP 模块。
Transformer 中的一层 FFN 可以简化为:
FFN(x) = down_proj( activation(gate_proj(x)) ⊙ up_proj(x) )
在 MoE 层中,会有多个这样的 FFN:
Expert 1: x -> FFN_1 -> y_1
Expert 2: x -> FFN_2 -> y_2
Expert 3: x -> FFN_3 -> y_3
...
Expert N: x -> FFN_N -> y_N
每个 Expert 都有独立参数,它们不一定对应人类语义的"数学专家"、"代码专家"或"中文专家",而是训练过程中自动形成的内部表示分工。
2.2 Router 路由
Router 一般是一个 Gate Network,负责为每个 token 选择应该使用哪些 Expert。
这个网络可以算化表示为:
其中:
- 是当前 token 的 hidden state。
- 是 router 参数。
- 是 token 被分配到各个 expert 的概率。
router 会选择概率最高的 Top-k 个 expert 来处理 token。
例如有 8 个 expert,Top-2 routing 可能得到:
token A -> Expert 2 + Expert 5
token B -> Expert 1 + Expert 2
...
token C -> Expert 7 + Expert 3
这就是稀疏激活:不是所有 expert 都参与计算,只有被路由选中的 expert 参与。
2.3 Combine 合并
Top-k routing 中,最终输出通常是被选中专家输出的加权和。
简单地可以表达为:
其中: 是被选中的专家, 是 router 给出的权重。
如果 k 太小,模型表达能力可能受限;如果 k 太大,MoE 会逐渐接近 dense 计算,失去稀疏激活的成本优势。
3. MoE 训练、推理、微调中的工程化
3.1 Load Balance 负载均衡
在常规的 MoE 训练中,Gate Network 会逐渐收敛,主要激活少数几个专家。这种现象会自我强化,因为受青睐的专家训练速度更快,因此被选中的次数也更多。
这会导致热门的 expert 过载而其它 expert 训练不足,进而带来 GPU 间通信的不平衡,最终导致训练吞吐下降和模型容量浪费。推理中也会遇到类似问题。
为了缓解这个问题,在规模化应用中保持负载均衡和效率,我们可以设置一个阈值 Capacity,限制单个专家可以处理的 token 数量,使 token 尽量更均匀地分配到不同 expert。
expert capacity 即指每个 expert 在一次 batch / micro-batch 中最多能处理的 token 数。
通常由公式
expert_capacity = ceil(tokens_per_batch × top_k / num_experts × capacity_factor)
来决定。
举个例子:
假设:
tokens_per_batch = 4096
top_k = 2
num_experts = 16
capacity_factor = 1.25
那么:
capacity = 4096 × 2 / 16 × 1.25 = 640
即平均每个 expert 理论上接收 640 tokens.
如果某个 expert 被分配的 token 数超过了 capacity,即出现了 overflow (溢出)。
对于溢出,系统一般会实现采取容量裁剪策略。常见处理方式包括:
- Reroute 改派: 使用备选 expert 或二级路由
- 在首选 expert 已满时,尝试将 token 分配给次优 expert。
- Drop 丢弃 - 丢弃超出 capacity 的 expert dispatch
- 对于 Top-1 路由,等价于该 token 跳过 MoE 分支;
- 对于 Top-2 / Top-k 路由,通常只是丢弃其中某个 expert 分支,token 仍可能由其他已成功分配的 expert 处理。
- error or fallback - 触发实现层面的异常或降级逻辑
- 如果框架要求严格容量约束,并且当前实现没有定义 overflow 处理策略,可能会直接报错
- 也可能进入实现预设的 fallback 逻辑。
当然,负载均衡不是越平均越好。如果强行平均,可能破坏模型自然形成的专家分工。所以,工程上需要在"有效分工"和"负载均衡"之间折衷。
3.2 Expert Parallel 专家并行
MoE 模型参数量大、专家数量多,通常需要分布式并行。
常见的并行方式是 EP (Expert Parallel 专家并行) - 把不同 expert 放到不同 GPU 上。
简化示意:
GPU 0: Expert 0, Expert 1
GPU 1: Expert 2, Expert 3
GPU 2: Expert 4, Expert 5
GPU 3: Expert 6, Expert 7
推理或训练时,token 会根据 router 结果被发送到对应 expert 所在的 GPU,计算后再汇总回来。
典型流程如下:
本地 token
-> router: 决定使用哪些 expert
-> dispatch: GPU all-to-all 通信 发送 token 到 expert 所在 GPU
-> expert 计算
-> GPU all-to-all 通信 返回结果
-> combine
因此,MoE 的性能瓶颈不只来自计算,还涉及通信和专家负载不均衡。
单机多卡中,NVLink / PCIe 差异会影响性能;多机训练中,网络带宽和延迟会更加关键。
3.3 训练
MoE 训练的核心关注点是让 router、expert 和分布式执行 同时稳定工作。
首先,对于 router,训练时要保证各个 expert 都能训练充足进而各个 expert 都能充分利用,通常需要引入一些 Load Balance 措施,例如 load balancing loss、router z-loss 或 router jitter noise,用于缓解路由塌缩和概率分布过度集中。
其次,单个 expert 在每一步看到的数据通常少于 dense FFN。即使模型总参数量很大,每个 expert 的有效训练样本也可能不足。因此,MoE 更依赖足够大的 batch、更稳定的数据分布,以及对 expert utilization 的持续监控。
另外,MoE 训练需要设置和控制 expert capacity。当出现 overflow 时会触发 reroute 或 drop。drop 会造成部分 expert 分支的训练信号丢失;capacity factor 过大又会增加显存、buffer 和通信开销。因此,capacity factor、batch size、sequence length、top_k 和 num_experts 需要一起调节。
所以,训练 MoE 模型时需要重点关注:
- router entropy 是否过低,避免 router 过早集中到少数 expert。
- expert utilization 是否均衡,避免部分 expert 长期训练不足。
- dropped tokens 是否过多,避免 capacity 设置过小导致训练信号损失。
- all-to-all time 是否成为瓶颈,避免通信开销吞掉稀疏激活带来的收益。
- loss 曲线是否出现异常波动,排查 router、capacity 或数据分布问题。
采用的策略一般有:
- 引入 load balancing loss 或 router z-loss,约束 router 分布。
- 调整 capacity factor,降低 overflow 与 dropped tokens 风险。
- 使用 router jitter noise 或 expert dropout,提升路由探索和训练鲁棒性。
- 增大 batch 或优化 batch 组织,使每个 expert 获得更稳定的样本。
- 在 EP 场景下优化 all-to-all 通信和 token dispatch,降低跨设备瓶颈。
3.4 推理
MoE 推理的主要优势在于稀疏激活:每个 token 通常只会路由到少数几个 expert,因此单 token 的计算量不随总参数量线性增长。
不过,这种稀疏激活结构也会带来额外的成本,主要包括:
- Router 路由: 需要通过 router 为每个 token 计算 expert 选择结果。
- dispatch 分发: 需要将 token 分发到对应 expert,在完成计算后需要回传。在 EP 中还会涉及通信开销。
- combine 合并: 在 expert 计算后需要重新聚合结果。
- 负载不均衡开销:如果部分 expert 被频繁选中,会造成热点 expert,影响整体吞吐和延迟。
- 执行组织复杂度:由于不同 expert 接收的 token 数不同,batch 组织、kernel 调度、padding / packing 等实现会比 dense 模型更复杂。
因此,MoE 推理是用较低的激活计算量,换来了更复杂的路由、通信和调度成本。
推理服务中需要关注:
| 问题 | 影响 |
|---|---|
| 推理框架是否支持该 MoE 结构 | 决定模型能否加载和加速 |
| Top-k - 每 token 激活几个 expert | 影响计算量和模型质量 |
| batch 内 token 路由是否均衡 | 影响吞吐和延迟 |
| EP: expert 分布在哪些 GPU | 决定通信路径和显存布局 |
所以,MoE 模型推理的实际性能取决于框架实现、并行策略、batch 组织和硬件互联等。
3.5 微调
与 dense 模型相比,MoE 的参数结构更分散。除了 Attention、Norm、Embedding 等公共参数外,还包括 router 和大量 expert 参数。
而 MoE 微调的关键问题是:微调应该改变哪些参数,以及是否会破坏原有的 expert 分工。
不同微调策略会影响成本、泛化能力和路由行为:
| 策略 | 适用场景 | 主要风险 |
|---|---|---|
| 冻结 router,只微调部分 expert | 任务范围较窄、希望控制成本 | 覆盖能力有限,可能只改善少数路由路径 |
| 冻结 router,微调全部 expert | 任务覆盖较广、需要保留路由结构 | 显存和训练成本较高 |
| 微调 router | 需要改变 token 到 expert 的分配策略 | 容易破坏已有 expert 分工,导致能力回退 |
| LoRA 到 expert / Attention | 参数高效微调 | target_modules 需要与模型结构和框架实现匹配 |
| 冻结 expert,训练 adapter | 希望最大限度保持原模型能力 | 适配能力可能受限 |
一般情况下,
- 如果目标是领域适配或指令微调,优先考虑冻结 router,并对 Attention、部分 expert 或全部 expert 做参数高效微调。
- 只有在明确需要改变路由行为时,才应考虑微调 router。
微调过程中需要重点关注的有:
- 数据是否覆盖足够多的路由模式,避免少数 expert 被过度调整。
- expert utilization 是否在微调前后明显偏移,避免路由分布塌缩。
- router 是否被冻结;如果未冻结,需要监控 router entropy 和负载均衡指标。
- LoRA target_modules 是否覆盖实际生效的 expert FFN,而不是只作用在 dense 层。
- 微调后是否在通用能力、目标任务和长上下文场景上分别评估,避免局部任务收益掩盖整体退化。
4. 实践
4.1 常见指标
理解和评估 MoE 时,可以关注以下指标:
| 指标 | 含义 |
|---|---|
| total parameters | 模型总参数量 |
| active parameters | 每 token 激活参数量 |
| num_experts | expert 总数 |
| top_k | 每个 token 选择几个 expert |
| expert capacity | 每个 expert 可接收 token 上限 |
| dropped tokens | 因容量不足被丢弃的 token |
| load balance loss | 负载均衡辅助损失 |
| expert utilization | 各 expert 被使用的比例 |
| all-to-all time | 专家并行通信耗时 |
| router entropy | router 分布是否过度集中 |
这些指标不仅影响训练效果,也影响推理性能和线上稳定性。
4.2 使用建议
使用 MoE 模型进行推理、微调、量化时,可以参考以下检查清单:
- 推理
- 查看总参数量和激活参数量,评估所需要的显存与算力。
- 确认推理框架是否支持该模型的 MoE 结构。
- 确认硬件和推理框架是否支持和需要 expert parallel等。
- 性能:使用真实输入长度和并发做压测 - 观察 TTFT、ITL、吞吐、显存和 expert 利用率。
- 量化:量化或格式转换后重新评估质量和性能。
- 微调:微调时确认 router、expert 和 LoRA target_modules 的策略。
总结
MoE 架构的本质是:用多个 expert 扩大模型总容量,再通过 router 让每个 token 只激活少数 expert,从而在容量和计算成本之间取得折中。
它的核心链路可以概括为:
token hidden state
-> router 选择 Top-k expert
-> 激活 expert 分别计算
-> 按 router 权重合并输出
MoE 能带来更大的模型容量和更低的相对激活计算量,但也引入了路由、负载均衡、专家并行、设备通信、量化和部署复杂度。