ChatGPT Images 2.0 图像生成实测
ChatGPT Images 2.0 的介绍、特点与实测。
OpenAI 在 2026年4月21日发布图像生成模型 ChatGPT Images 2.0,宣布图像生成新时代的来临。
介绍
ChatGPT Images 2.0 在上一代图像生成模型的基础上更进一步:能够处理复杂的视觉任务,并生成精准且可立即使用的视觉效果。
Images 2.0 是 OpenAI 首个具备思考能力的图像模型,扩展了模型处理复杂任务的能力。
在 ChatGPT 中选择思考模型后,Images 2.0 可以搜索网络获取实时信息,根据一个提示创建多个不同的图像,并对其输出进行双重检查。凭借思考能力,该模型可以承担更多从想法到图像的繁重工作,尤其是在准确性、信息时效性、一致性和视觉连贯性至关重要的情况下。
并且,从当天起,所有 ChatGPT、Codex 和 API 用户均可使用该模型。
在 ChatGPT 中选择“思考模式”后,模型会花费更多时间,并在后台进行更多自主操作,以彻底理解并执行任务。它可以利用网络查找相关信息,将上传的素材转化为清晰的视觉解释,并在生成图像前分析图像结构。在这种模式下,Images 2.0 更像是视觉思维伙伴,能够将项目从粗略的概念转化为最终的成品,无需投入太多人工精力。Codex 也接入了新模型,可以直接使用。
特点
ChatGPT Images 2.0 相对于其它图像生成模型在下面几方面有更好的表现:
极强的跨语言能力
不仅字母文字的精度更高,本次模型升级后,在非字母文字方面的表现也有显著进步,不仅能正常渲染出文字,还能将文字融入设计。
风格上的精致与现实主义
在各种视觉风格上都展现出了更高的保真度,在纹理、光照、构图和细节方面都能保持高一致性。
提供了更灵活的宽高比
能够生成符合您各种需求的输出格式,从宽幅横幅和演示幻灯片到海报、移动设备屏幕、书签和社交媒体图片,应有尽有。
现实世界智能 将更贴近时代的世界认知融入图像创作,其智能化功能使其能够出色地完成端到端的任务。
当然,官方也指出了模型当前的局限性,难以处理的场景有下面几个:
- 需要完整且连贯的物理世界模型、折纸指南、魔方等谜题。
- 需要在隐藏、倾斜或反转表面上正确显示的细节。
- 非常密集或重复的视觉细节,例如细小的沙粒,也可能考验模型的极限。
- 标签和图表的准确性仍需审核,尤其是在依赖精确箭头或部件标签的情况下。
模型实测
下面是在 chatGPT 中进行图像生成的 Artifacts。
- UI图
- 多语言中文漫画
- 手写稿
- 人物关系图
- 汽车拆解
- 羽毛球技术
Prompt
帮我生成一张APP图片,里面是用户餐食打卡和菜品推荐、营养知识等功能
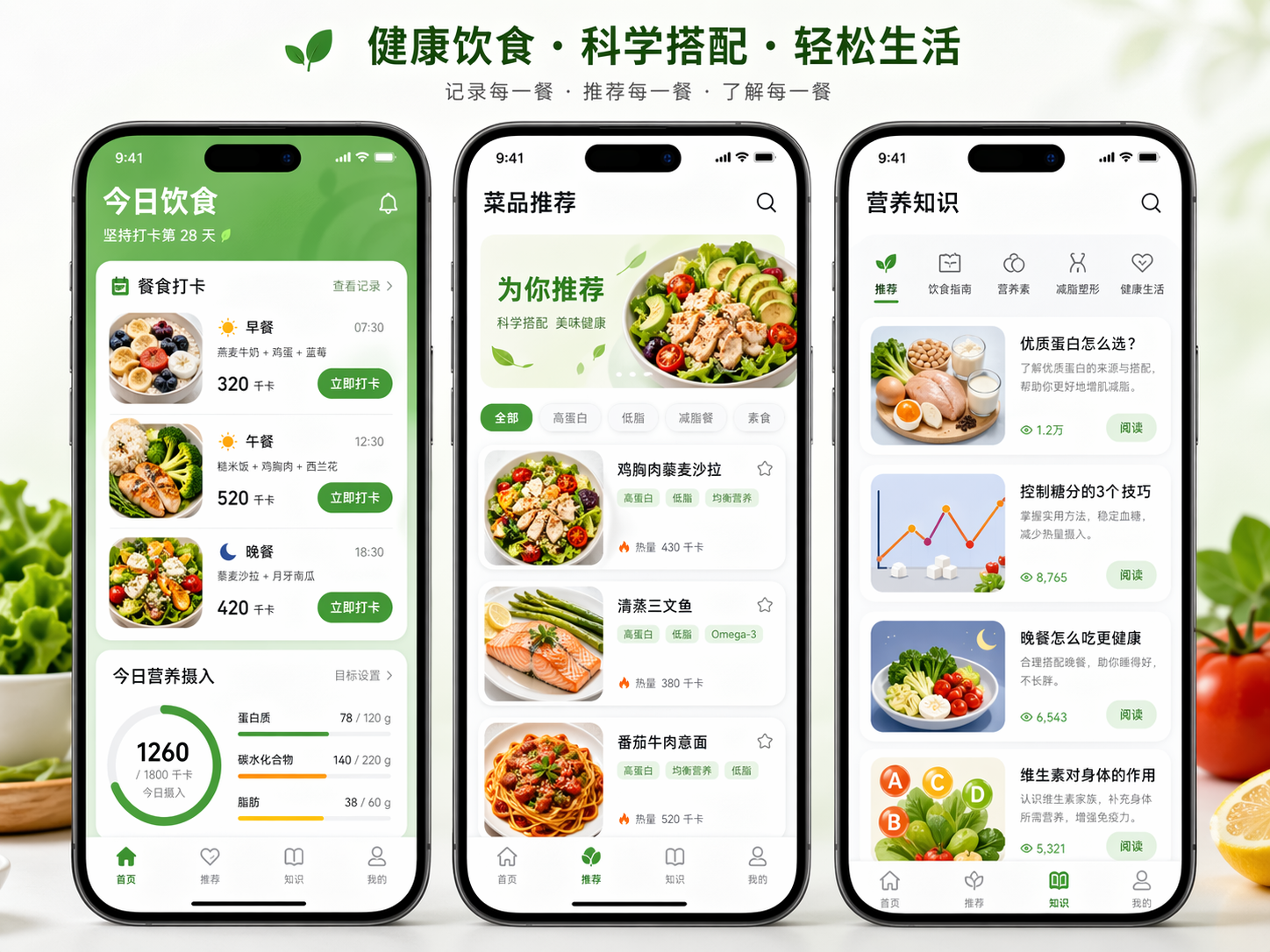
Prompt 只有简单的一句话
但在思考模式下,模型补全了功能和交互细节(比如菜品标签、知识分类等),甚至还有APP的定位、slogon等
并且中文字符渲染完全没有问题。
画面精美,可以直接做为APP的宣传海报了。
官方示例中让我印象最深刻的是 *Chinese comic*:多种语言都成正确渲染,并且官方自己也玩了 "稳稳地接住你" 这个梗
我也参考官方提示词生成了一张类似的

可以看到生成的漫画风格一致性保持得非常不错。
但是这个梗我没看懂。
一份小馆的手写菜单

中文字符完全正确,价格也合逻辑。甚至右侧的声明也很真实。
足以以假乱真了。
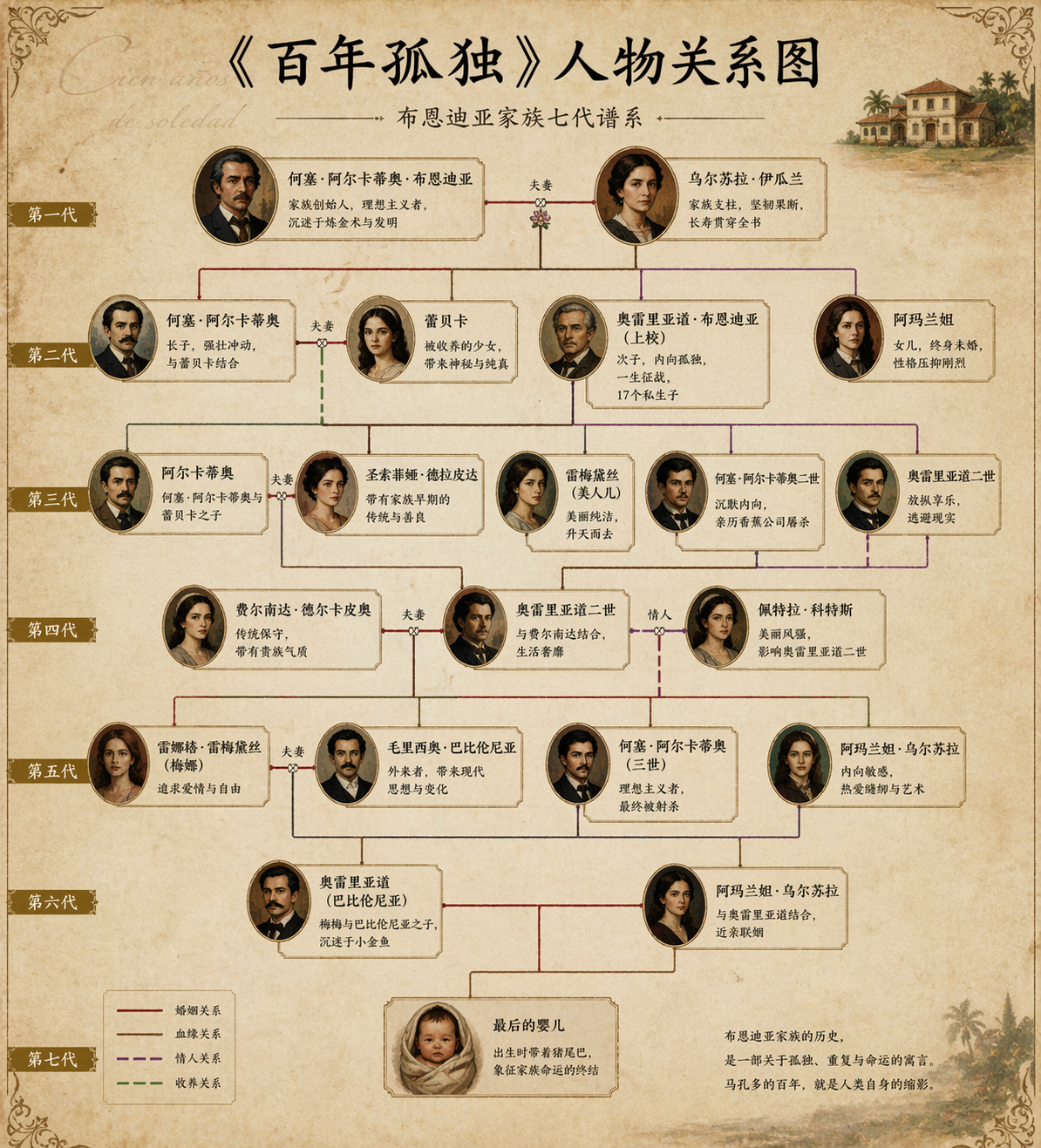
《百年孤独》人物关系图
汽车技术拆解:新能源技术、自动驾驶技术、爆炸图

有些标识有问题,但对于这么复杂和高信息度的图来说,模型表现可以说是相当不错了。
关于人物动态等
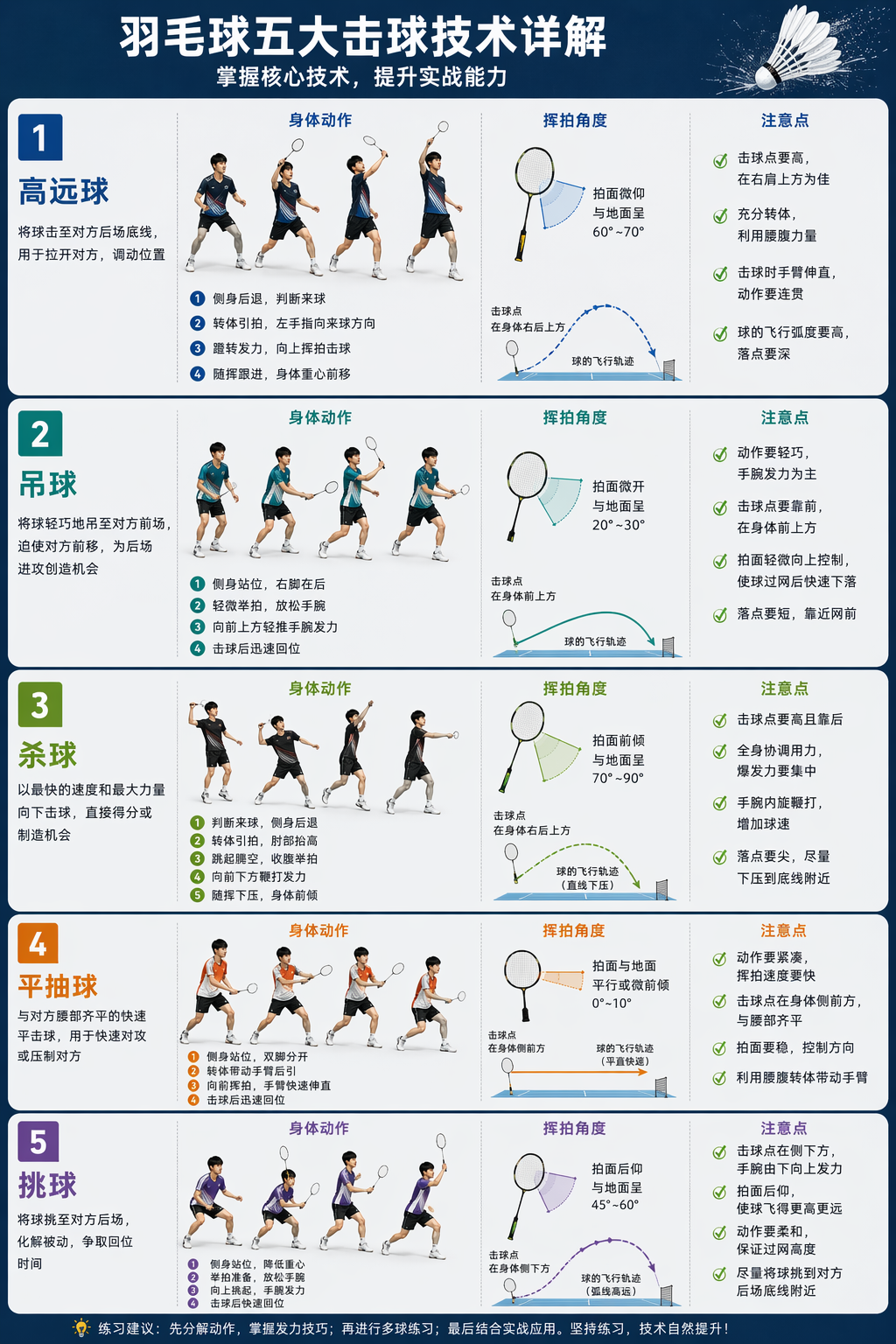
有些图像元素错位了,但整体上是正确的。
总结
从对多语言的掌握、风格的一致性、写实水平和审美水平方面看, ChatGPT Images 2.0 在图像生成领域绝对达到 SOTA 水平。
ChatGPT Images 2.0 的出现,意味着AI生成图片可以直接进入营销、教育、设计与内容生产流程,也促使图像模型接下来会越来越像创意生产工具链的一环,而不是单独的生成入口。